認定整備済みのiPad(Appleが提供している中古品)の購入を検討していたのだが、新たに商品が追加されていないか確認するため定期的にWebサイトを訪れていた。毎回サイトを見に行くのは面倒なため、自動で定期的にチェックして商品の入れ替えがあれば自分に通知するようにする。以前、セ・リーグの順位表をスクレイピングする方法を「AWS Lambdaで定期的にスクレイピングする方法(その3)」で紹介したが、そのLambdaを改良してAppleのiPad整備済製品を定期的にスクレイピングする。
目次
修正前のソース
以下の2つのブログをチェックしていた。scraping-functionの修正ソースを転記する。
import json
import urllib.parse
import boto3
import datetime
from datetime import timedelta, timezone
import random
import os
import requests
from bs4 import BeautifulSoup
import difflib
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
def lambda_handler(event, context):
mail = 'xxx@gmail.com'
contents_name = ['Fujii', 'Kyoko']
url = [
'http://shogidata.com/soutaschedule/',
'https://blog.goo.ne.jp/kyouko_sensei',
]
selecter = [
'#the-content',
'#in-center > div > div.content-body > div:nth-child(1) > div.entry',
]
for i in range(len(url)):
state = main(mail, contents_name[i], url[i], selecter[i])
if state == False:
return {
'statusCode': 200,
'body': json.dumps('Error occurred. ' + contents_name[i])
}
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}
def main(mail, contents_name, url, selecter):
file_contents = ''
state = ''
exist_contents = ''
try:
#Get existing data
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
exist_contents = exist_data['Item']['Contents']
except KeyError:
print('Not found data. OK. Insert new data.')
except Exception as e:
print('Select DB Error!!!')
print(e)
return False
file_contents = scraping_selecter(contents_name, url, selecter)
if file_contents == False:
return False
try:
if file_contents != exist_contents:
print('changed!')
state = 'changed!'
res = difflib.ndiff(exist_contents.split(), file_contents.split())
sabun = ''
for r in res:
if r[0:1] in ['+']:
sabun = sabun + r + '\n'
#if the data has been altered,
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'Contents': file_contents,
'ContentsTranslate': '',
'Sabun': sabun,
'SabunFlag': True,
'Selecter': selecter,
'UpdateFlag': 1,
'URL': url,
}
)
else:
print('same...')
state = 'same...'
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
return False
return state
#Get data by scraping.
def scraping_selecter(contents_name, url, selecter):
file_contents = ''
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.select(selecter)
for e in obj:
file_contents = e.text
if file_contents == '':
print('not found selecter...')
return False
except Exception as e:
print('Scraping Error!!! ' + contents_name)
print(e)
return False
return file_contentsLambda1:iPad整備品をチェック
最初、Chromeで右クリック→コピー→selectorをコピーで、selectorを指定しようとしたがうまくいかず、find_all(‘h3’, ‘rf-refurb-producttile-title’)で、h3タグ+クラス名で取得しようとしてもうまくいかなかった。Chromeのデベロッパーツールで見ると、h3タグにクラス名が含まれているのだが・・・。
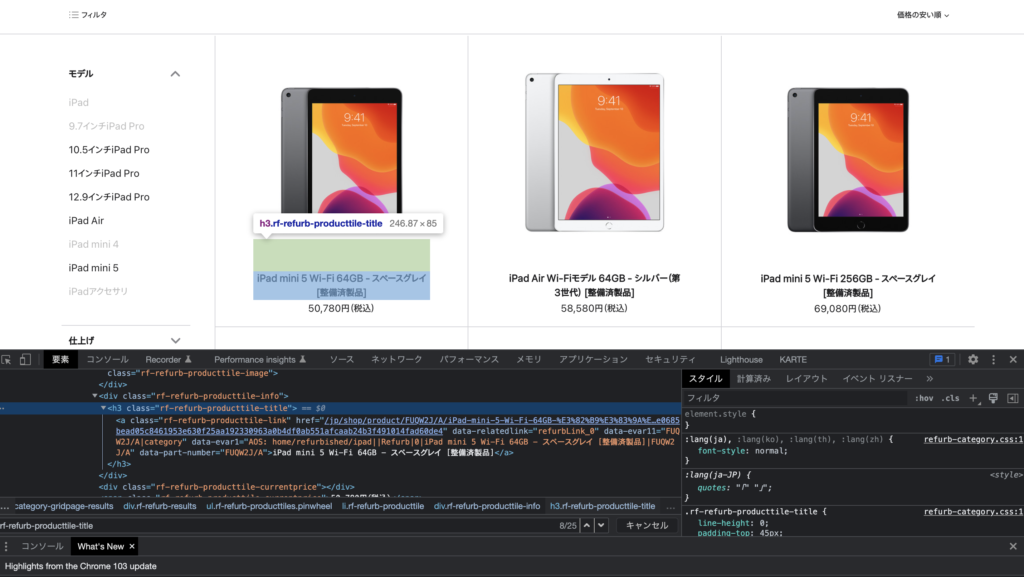
右クリック→「ページのソースを表示」で見ると、h3にクラス名がついていない。
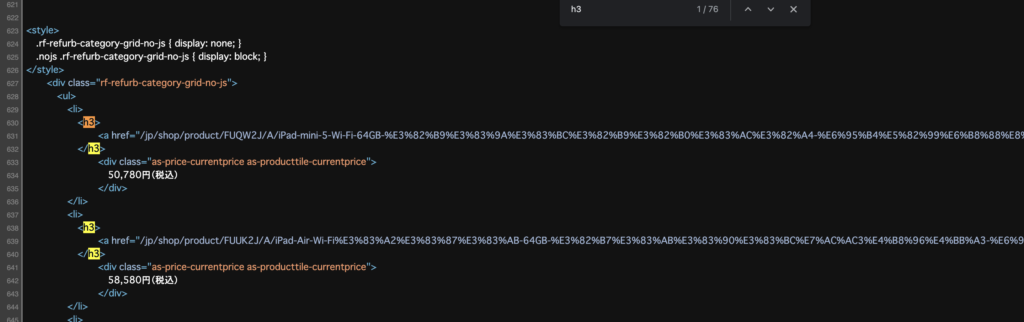
おそらくJSで動的にクラス名を付与しているのだと思われる。BeautifulSoapの弱点はJSで動的に生成されたHTMLソースに対応していない点である。今回、URLも取得できる aタグを取得する(※後日、今回のURLは毎日変動するため意味がなかった)。ただし、すべてのaタグを取得するとゴミデータが混じるため「iPad」「[整備済製品]」のワードが含まれる場合のみとする。
余談だが、BeautifulSoapのリファレンスのfind_all() で調べていたのだが、非常に理解が難しい。
import json
import urllib.parse
import boto3
import datetime
from datetime import timedelta, timezone
import random
import os
import requests
from bs4 import BeautifulSoup
import difflib
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
def lambda_handler(event, context):
mail = 'xxx@gmail.com'
contents_name = ['Fujii', 'Kyoko', 'ipad']
url = [
'http://shogidata.com/soutaschedule/',
'https://blog.goo.ne.jp/kyouko_sensei',
'https://www.apple.com/jp/shop/refurbished/ipad',
]
selecter = [
'#the-content',
'#in-center > div > div.content-body > div:nth-child(1) > div.entry',
'',
]
for i in range(len(url)):
state = main(mail, contents_name[i], url[i], selecter[i])
if state == False:
return {
'statusCode': 200,
'body': json.dumps('Error occurred. ' + contents_name[i])
}
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}
def main(mail, contents_name, url, selecter):
file_contents = ''
state = ''
exist_contents = ''
try:
#Get existing data
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
exist_contents = exist_data['Item']['Contents']
except KeyError:
print('Not found data. OK. Insert new data.')
except Exception as e:
print('Select DB Error!!!')
print(e)
return False
if contents_name == 'ipad':
file_contents = scraping_ipad(contents_name, url)
else:
file_contents = scraping_selecter(contents_name, url, selecter)
if file_contents == False:
return False
try:
if file_contents != exist_contents:
print('changed!')
state = 'changed!'
res = difflib.ndiff(exist_contents.split(), file_contents.split())
sabun = ''
for r in res:
if r[0:1] in ['+']:
sabun = sabun + r + '\n'
#if the data has been altered,
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'Contents': file_contents,
'ContentsTranslate': '',
'Sabun': sabun,
'SabunFlag': True,
'Selecter': selecter,
'UpdateFlag': 1,
'URL': url,
}
)
else:
print('same...')
state = 'same...'
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
return False
return state
#Get data by scraping.
def scraping_selecter(contents_name, url, selecter):
file_contents = ''
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.select(selecter)
for e in obj:
file_contents = e.text
if file_contents == '':
print('not found selecter...')
return False
except Exception as e:
print('Scraping Error!!! ' + contents_name)
print(e)
return False
return file_contents
def scraping_ipad(contents_name, url):
file_contents = ''
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.find_all('a')
for e in obj:
if (e.text).find('iPad') > 0 and (e.text).find('[整備済製品]') > 0:
#URLが毎回変動するため却下
#file_contents += '■' + e.text + '\n' + e.get('href') + '\n\n'
file_contents += '■' + e.text + '\n'
if file_contents == '':
print('not found iPad.OK.')
except Exception as e:
print('Scraping Error2!!! ' + contents_name)
print(e)
return False
return file_contents
Lambda2:差分をメール通知
当初作成したソースを改良する。改良点は以下の通り。
- パーティションキー + ソートキーを指定→1件取得のget_item()をやめ、全データを取得するquery()を使う(厳密にはパーティションキーのみ指定)。
- メールの件名に固有の名称をつけ、識別しやすくする。
Boto3リファレンスの query() を調べていたのだが、こちらも非常に理解が難しい。
以下のようにpublishメソッドのパラメータにSubjectを追加することで、通知メールの件名を指定することができる。
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:xxx:NotifyScraping',
Message = contents_name + ' has been updated.' + '\n\n' + body,
Subject = contents_name + ':通知メール',
)以下が修正済みソース。
import json
import boto3
from boto3.dynamodb.conditions import Key
sns_client = boto3.client('sns')
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
sns_client = boto3.client('sns')
def lambda_handler(event, context):
mail = 'xxx@gmail.com'
state = main(mail)
if state == False:
# Error! Email notification.
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:xxx:NotifyScraping',
Message='notify-scraping-function error is occured!',
)
return {
'statusCode': 200,
'body': json.dumps('Process aborted because an error occurred. ')
}
return {
'statusCode': 200,
'body': json.dumps('The Notify process is complete.')
}
def main(mail):
# Check it has been updated.
try:
#Get existing data
exist_data = scraping_table2.query(
KeyConditionExpression=Key('Mail').eq(mail)
)
items = exist_data['Items']
for item in items:
contents_name = item['ContentsName']
update_flag = item['UpdateFlag']
contents = item['Contents']
contents_translate = item['ContentsTranslate']
sabun = item['Sabun']
sabun_flag = item['SabunFlag']
url = item['URL']
selecter = item['Selecter']
if update_flag == 1:
print(contents_name + ' changed!')
if contents_translate != '':
body = contents_translate + '\n\n'
else:
body = contents + '\n\n'
body += url + '\n\n'
if sabun_flag == True:
body += sabun + '\n\n'
# Email notification as it is updated.
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:xxx:NotifyScraping',
Message = contents_name + ' has been updated.' + '\n\n' + body,
Subject = contents_name + ':通知メール',
)
# Reset the UpdateFlag.
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'Contents': contents,
'ContentsTranslate': contents_translate,
'Sabun': sabun,
'SabunFlag': sabun_flag,
'Selecter': selecter,
'UpdateFlag': 0,
'URL': url,
}
)
else:
print(contents_name + ' same..')
except Exception as e:
print('Select or Pulbish or Update Error!!!')
print(e)
return False
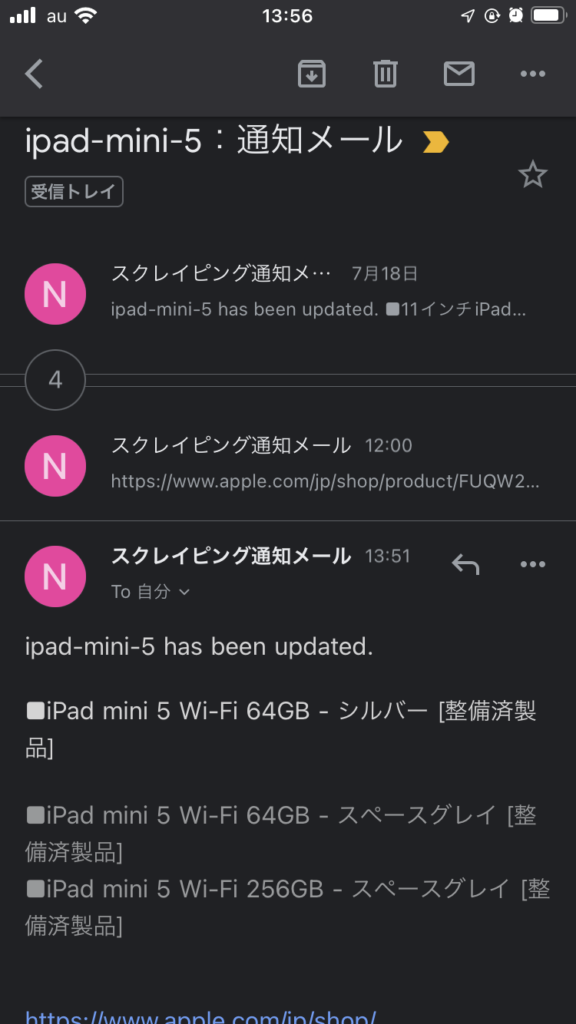
return True以下のようにメール通知される(今回の場合、iPad mini 5に絞り込んだ)。
まとめ
このように定期的にチェックできれば新商品が入荷した場合もすぐに対応ができる。次は、Parallels DesktopのWebサイトの新製品を定期的にチェックしようと思う。