Twitterで日本語以外のツイートを自動で翻訳・お知らせするプログラムを作る。前回「AWS LambdaでTwitterのお気に入りユーザーのツイートを定期的にスクレイピング」で作ったLambdaを改良する。

前回のおさらいと今回の構成
前回、「AWS LambdaでTwitterのお気に入りユーザーのツイートを定期的にスクレイピング」の構成図は以下になる。Amazon EventBridgeでcrontabのようにスケジュール実行を可能にし、Setp Functionsで、以下のLambdaの処理順序を制御する。
- Lambda(scraping-function)で特定のブログをスクレイピングしてDynamoDBに保存
- Lambda(twitter-function)で特定のTwitterをスクレイピングしてDynamoDBに保存
- Lambda(notify-scraping-function)で、DynamoDBから差分のみメール通知する
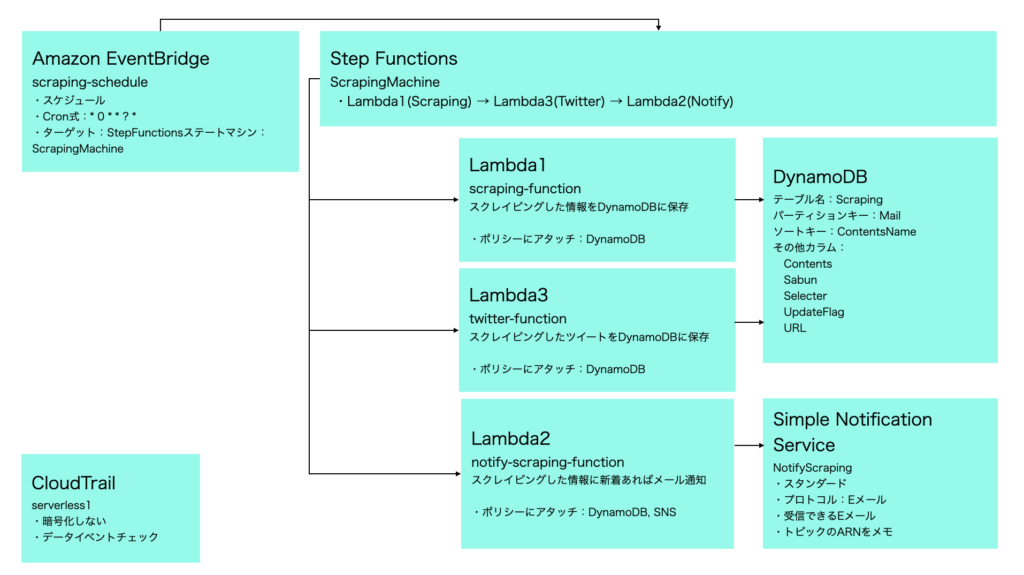
今回、twitter-functionでAmazon TranslateのAPIを使って、ゼレンスキーさんのツイートを翻訳し、DynamoDBに保存する。そして、notify-scraping-functionでは、翻訳前・翻訳後のツイートをメール通知する。

ツイートスクレイピングLambdaのソース
処理の流れは以下になる。
- DynamoDBに前回スクレイピングしたデータがあれば取得
- ゼレンスキーさんのツイート最新10件取得
- 翻訳必要パラメータありの場合、Amazon Translateで翻訳
- 前回スクレイピングと差分があればDynamoDBに保存
ポイントは以下の翻訳処理。取得後、DynamoDBの「ContentsTranslate」カラムに保存する。
translate_client = boto3.client('translate')
response = translate_client.translate_text(
Text = tweet_text,
SourceLanguageCode = translate_language,
TargetLanguageCode = 'ja'
)
translate_text = response.get('TranslatedText')「アクセス権限」の実行ロールに「TranslateFullAccess」ポリシーを割り当てておく。
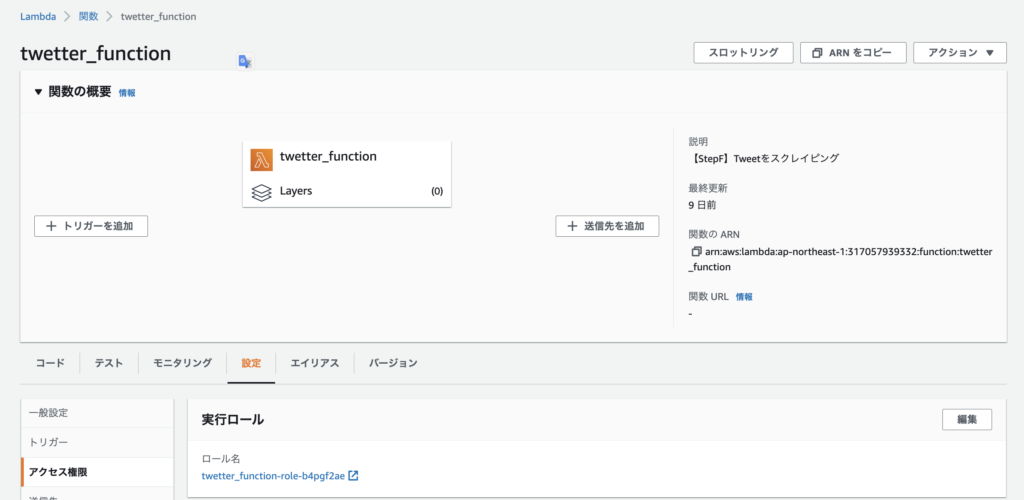
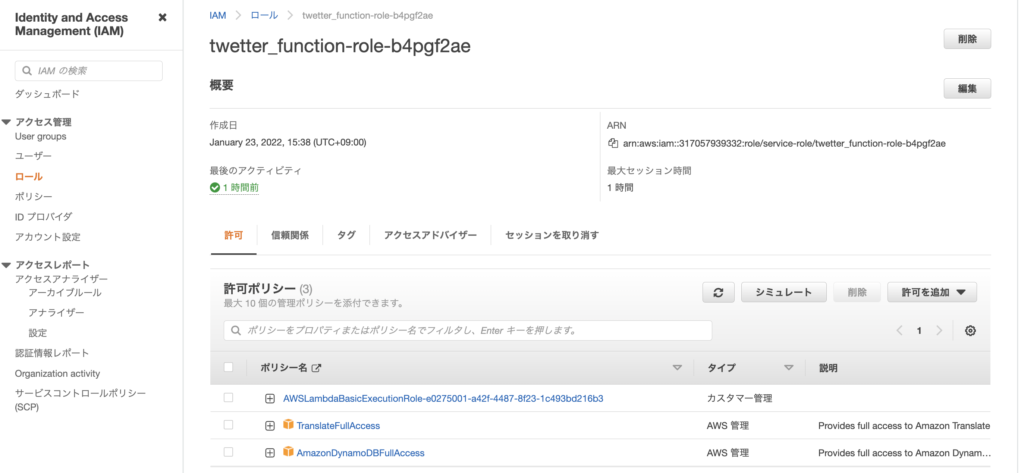
ソース全文はこちら。
import json
import boto3
import difflib
import tweepy
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
translate_client = boto3.client('translate')
api_key = "xxx"
api_key_secret = "xxx"
access_token = "xxx"
access_token_secret = "xxx"
bearer_token = "xxx"
def lambda_handler(event, context):
mail = 'xxx@gmail.com'
contents_name = ['ZelenskyyUa']
user_id = ['1120633726478823425']
translate_language = ['auto']
for i in range(len(user_id)):
state = main(mail, contents_name[i], user_id[i], translate_language[i])
if state == False:
return {
'statusCode': 200,
'body': json.dumps('Process aborted becaouse an error occurred. ' + contents_name[i])
}
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
def main(mail, contents_name, user_id, translate_language):
file_contents = ''
state = ''
exist_contents = ''
try:
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
exist_contents = exist_data['Item']['Contents']
except KeyError:
print('Not found data. OK. Insert new data.')
except Exception as e:
print('Select DB Error!!!')
print(e)
return False
file_contents = ''
file_translate = ''
try:
client = tweepy.Client(bearer_token, api_key, api_key_secret, access_token, access_token_secret)
buf = client.get_users_tweets(user_id, max_results=10, exclude=["replies"])
tweets_data = buf.data
for tweet in tweets_data:
url = 'https://twitter.com/' + contents_name + '/status/' + str(tweet.id)
tweet_text = tweet.text
translate_text = ''
if translate_language != '':
response = translate_client.translate_text(
Text = tweet_text,
SourceLanguageCode = translate_language,
TargetLanguageCode = 'ja'
)
translate_text = response.get('TranslatedText')
file_contents += url + "\n" + tweet_text + "\n\n"
if translate_language != '':
file_translate += url + "\n" + tweet_text + "\n↓\n" + translate_text + "\n\n"
if file_contents == '':
print('not found tweets...')
return False
except Exception as e:
print('Scraping Error!!! ' + contents_name)
print(e)
return False
try:
if file_contents != exist_contents:
print('changed!')
state = 'changed!'
res = difflib.ndiff(exist_contents.split(), file_contents.split())
sabun = ''
for r in res:
if r[0:1] in ['+']:
sabun = sabun + r + '\n'
#if the data has been altered,
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'Contents': file_contents,
'ContentsTranslate': file_translate,
'Sabun': sabun,
'SabunFlag': False,
'Selecter': '',
'UpdateFlag': 1,
'URL': 'https://twitter.com/' + contents_name,
}
)
else:
print('same...')
state = 'same...'
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
return False
return state
メール通知するLambdaのソース
処理の流れは以下になる。
- DynamoDBからupdate_flag=1のデータを取得
- メール本文を編集する(翻訳前+翻訳後)
- メール送信
- update_flag=0でUpdate
ソース全文はこちら。
import json
import boto3
sns_client = boto3.client('sns')
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
sns_client = boto3.client('sns')
def lambda_handler(event, context):
mail = 'xxx@gmail.com'
contents_name = ['ZelenskyyUa']
for i in range(len(contents_name)):
state = main(mail, contents_name[i])
if state == False:
# Email notification.
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:xxx:NotifyScraping',
Message='notify-scraping-function error is occured!'
)
return {
'statusCode': 200,
'body': json.dumps('Process aborted becaouse an error occurred. ' + contents_name)
}
return {
'statusCode': 200,
'body': json.dumps('The Notify process is complete.')
}
def main(mail, contents_name):
update_flag = 0
contents = ''
sabun = ''
url = ''
selecter = ''
try:
#Get existing data
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
update_flag = exist_data['Item']['UpdateFlag']
contents = exist_data['Item']['Contents']
contents_translate = exist_data['Item']['ContentsTranslate']
sabun = exist_data['Item']['Sabun']
sabun_flag = exist_data['Item']['SabunFlag']
url = exist_data['Item']['URL']
selecter = exist_data['Item']['Selecter']
except KeyError:
print('Not found data. OK. Do nothing.')
except Exception as e:
print('Select Error!!!')
print(e)
return False
if update_flag != 1:
print('No change, so normal termination.')
return True
print('change!')
try:
body = contents_name + '\n\n' + url + '\n\n'
if contents_translate != '':
body += contents_translate + '\n\n'
else:
body += contents + '\n\n'
if sabun_flag == True:
body += sabun + '\n\n'
# Email notification as it is updated.
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:xxx:NotifyScraping',
Message='The website has been updated as a result of scraping.' + '\n\n' + body
)
except Exception as e:
print('Publish Error!!!')
print(e)
raise False
# Reset the UpdateFlag.
try:
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'Contents': contents,
'ContentsTranslate': contents_translate,
'Sabun': sabun,
'SabunFlag': sabun_flag,
'Selecter': selecter,
'UpdateFlag': 0,
'URL': url,
}
)
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
raise False
return True通知されたメールは以下のようになる。
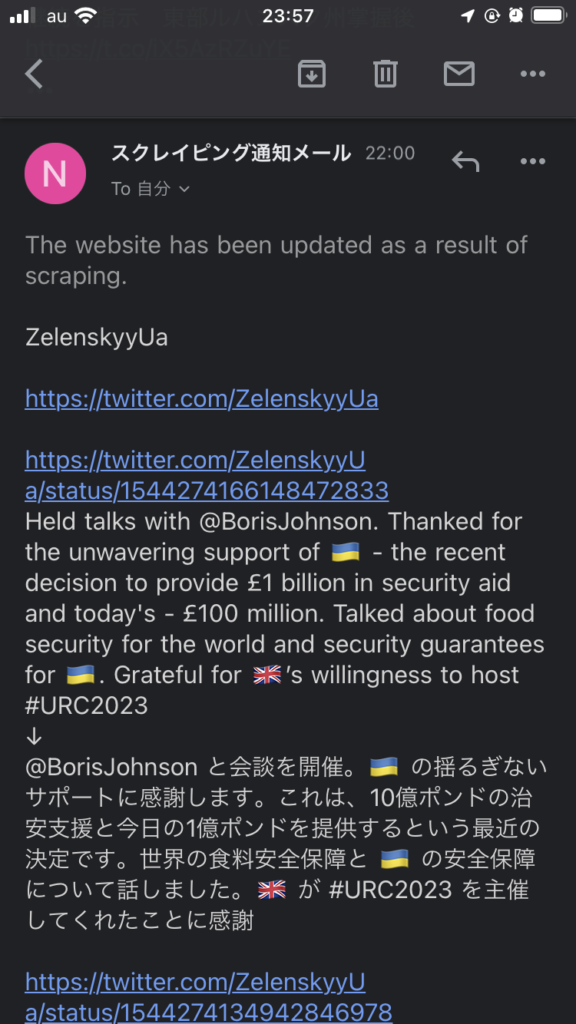
グレタ・トゥーンベリさんのツイートも取得可能に。
今回想定の検索ワード
”Lambda Twitter スクレイピング”