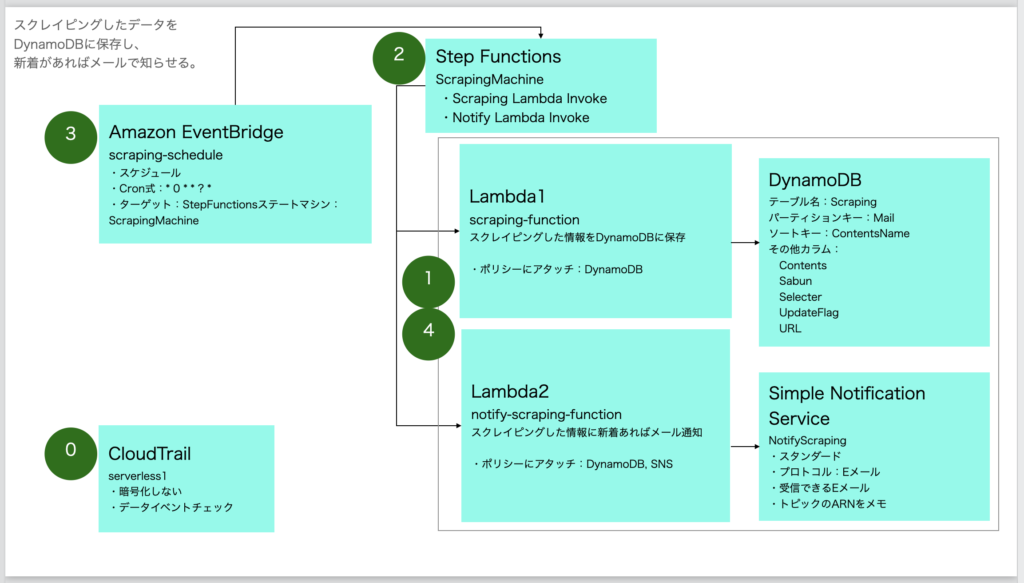
いよいよLambdaで定期的にスクレイピングする。単にスクレイピングするだけでは意味がないので、スクレイピングした結果をDBに保存し、次にスクレイピングする前に、前回保存したデータと差分があった場合のみメール通知するようにする。
目次
DynamoDBにテーブル追加
DynamoDBから「テーブルの作成」ボタンをクリック。
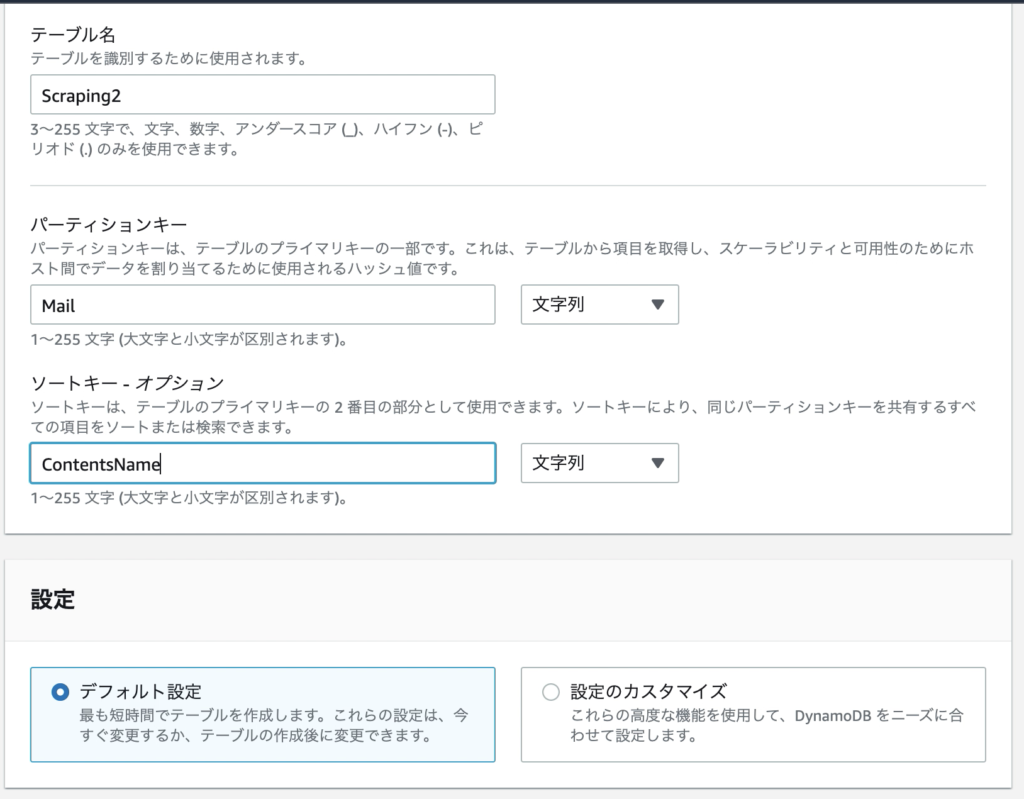
テーブル名を「Scraping2」、パーテションキーを「Mail」、ソートキーを「ContentsName」と入力。
これは、プライマリーキーを「Mail」+「ContentsName」とする意味になる。将来、ユーザー単位で情報を保存する場合に備えて「Mail」を第一のキーとし、一人のユーザーで複数サイトをスクレイピングするため、第2のキーとして「ContentsName」とした。例えば、以下のデータイメージである。
| ContentsName | Contents | |
| twinkangaroos@gmail.com | Fujii | (コンテンツの中身) |
| twinkangaroos@gmail.com | Tigers | (コンテンツの中身) |
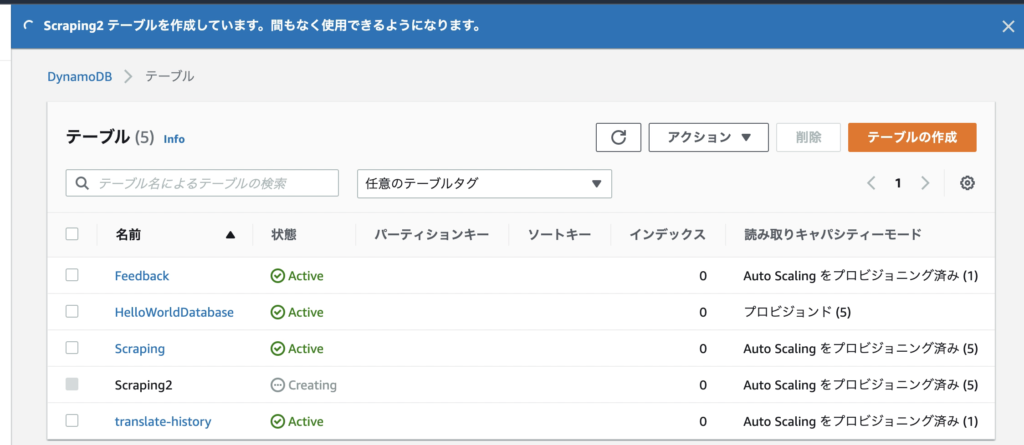
「テーブルの作成」ボタンをクリックし、しばらく待つと作成される。
レイヤーの作成
スクレイピングのライブラリであるBeautifulSoupをAWSのLambdaで使えるようにするため、AWSの「レイヤー」に追加する必要がある。
※ちなみに私は当初、ローカルでPythonのコードを書き、それをzipに固めてアップロードする方法を行っていたが、さすがに毎回アップロードするのはつらいため、今回のレイヤーを採用する方法を見つけ、感動した。こんなに楽になるものかと。以下の作者には感謝しかない。
■AWS Lambda python「デプロイパッケージが大きすぎてインラインコード編集を有効にできません」の回避方法 – Qiita
https://qiita.com/koji4104/items/a336b986ea934a3068b8
まずは、ローカルPC上で、以下のコマンドを実行し、ライブラリをフォルダに詰め込む。
mkdir python
pip3 install requests -t ./python/
pip3 install beautifulsoup4 -t ./python/
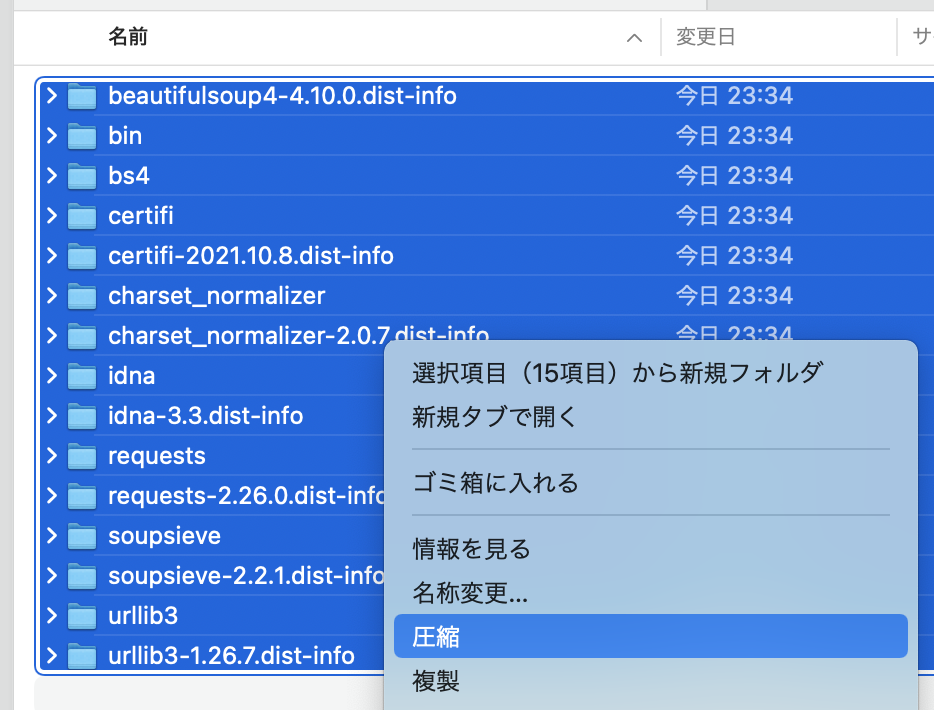
全ファイルを選択して「圧縮」し、圧縮したファイル名を「python.zip」とする。
「AWS Lambda」左メニューの「レイヤー」をクリックし、「レイヤーの作成」ボタンをクリック。
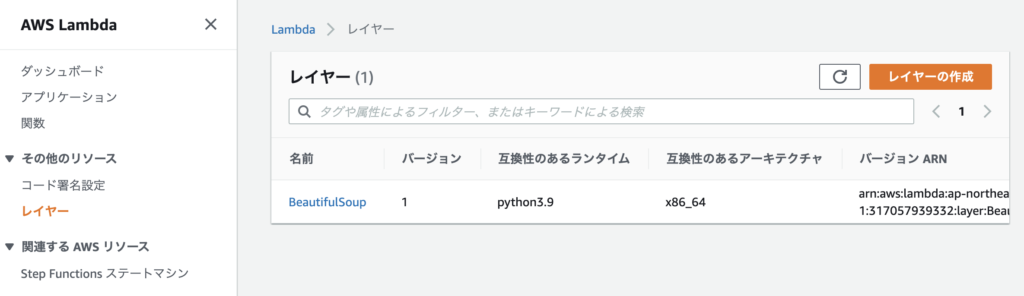
名前に「BeautifulSoup」と入力し、「.zipファイルをアップロード」を選択し、先ほど圧縮したpython.zipを選択する。

「x86_64」にチェックを入れ、互換性のあるランタイムに「Python 3.9」を選択する。そして「作成」ボタンをクリック。
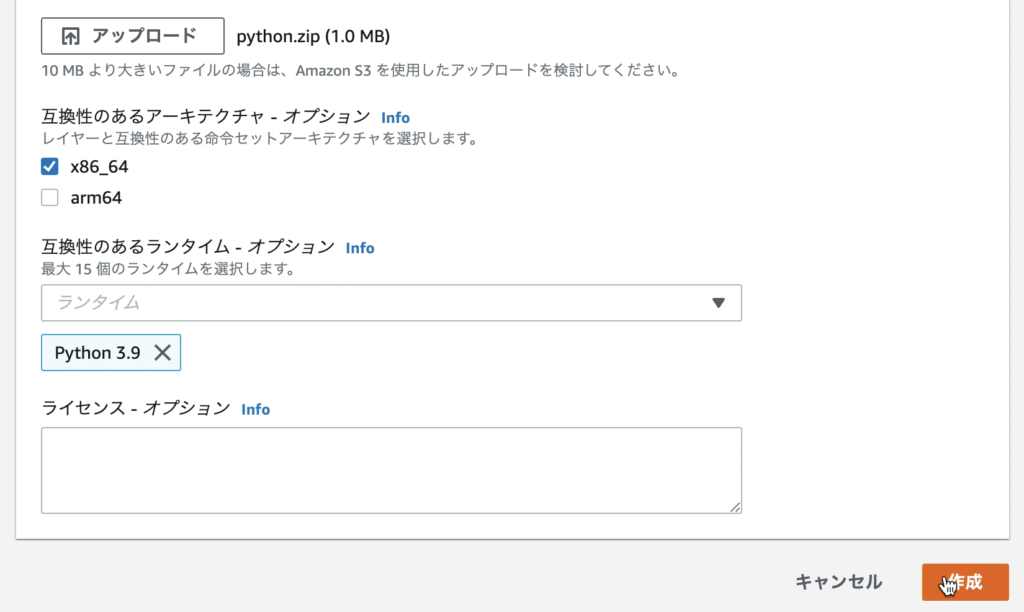
作成完了。
Lambda「scraping-function」を選択し、画面下の「レイヤーの追加」ボタンをクリック。

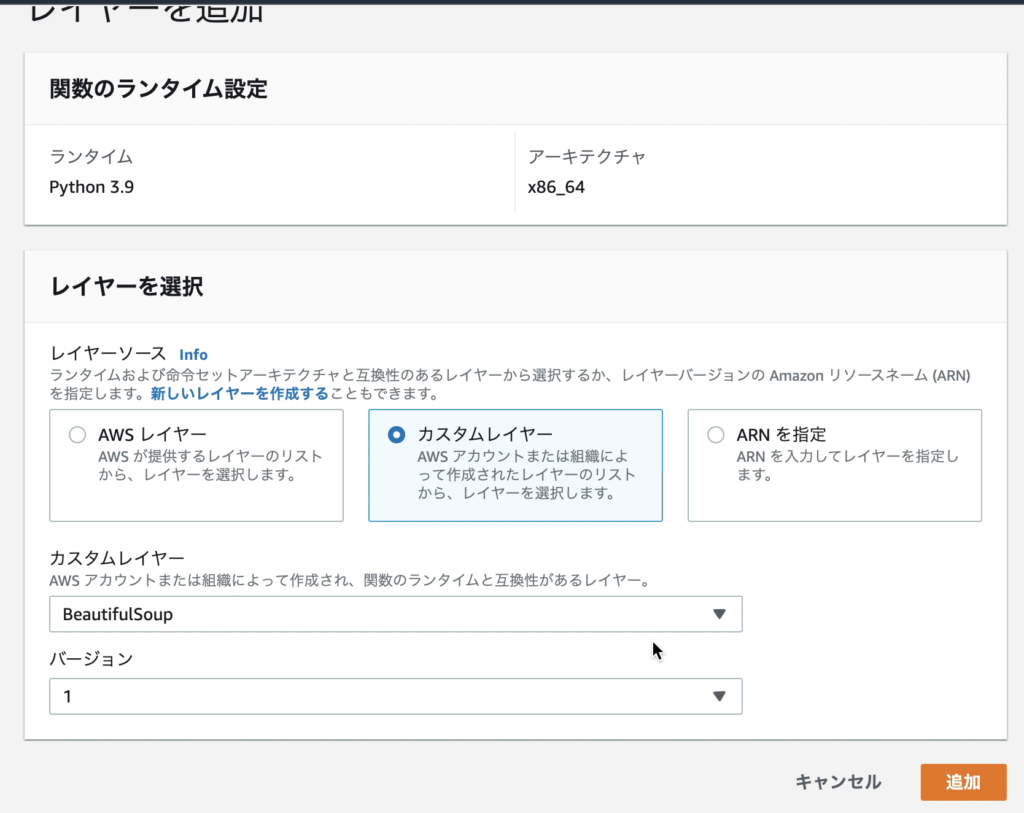
「カスタムレイヤー」を選択し、先ほど作成した「BeautifulSoup」を選択、バージョン「1」を選択して、「追加」ボタンクリック。
Lambdaの作成
Lambda1:スクレイピング結果をprint
これで準備は完了したので、スクレイピングするLambda関数を作る。
まず、例として、Yahooのセ・リーグの順位表をスクレイピングする。
■順位表 – プロ野球 – スポーツナビ
https://baseball.yahoo.co.jp/npb/standings/
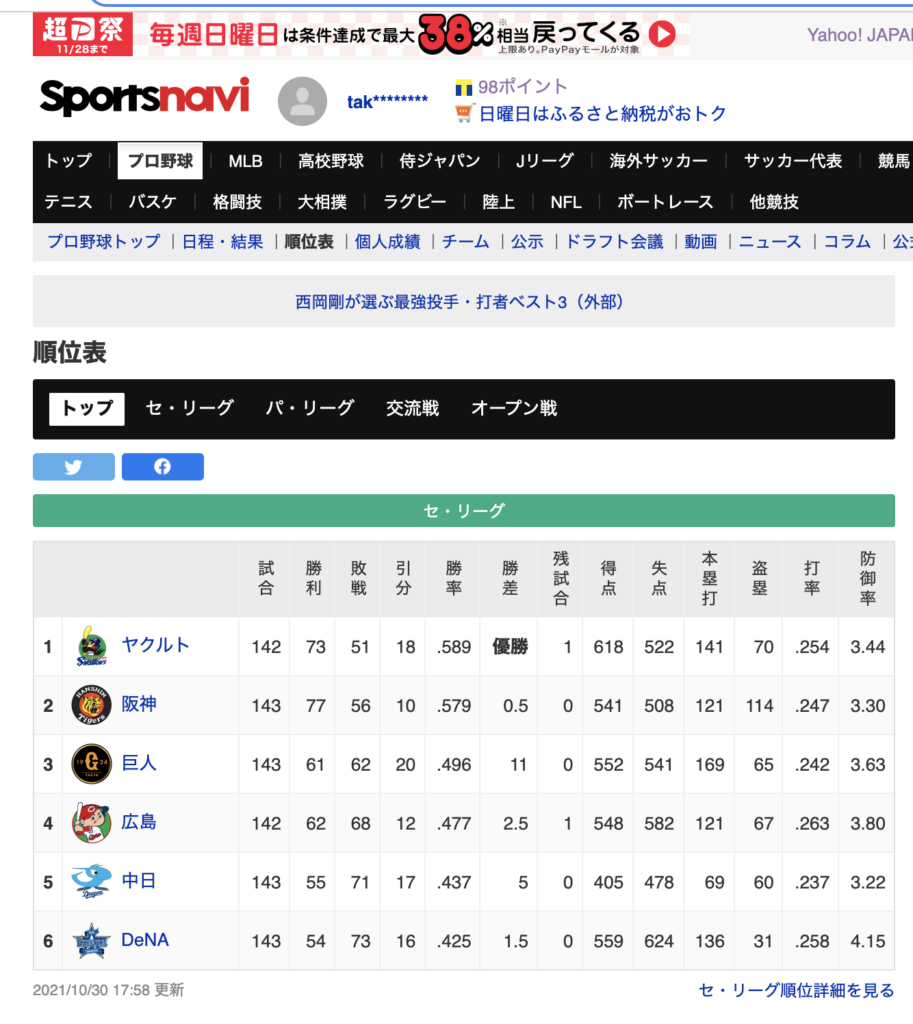
スクレイピングしたいエリア(今回はTableタグ)のselectorをコピーする(’#standing > section:nth-child(1) > section > table’)。
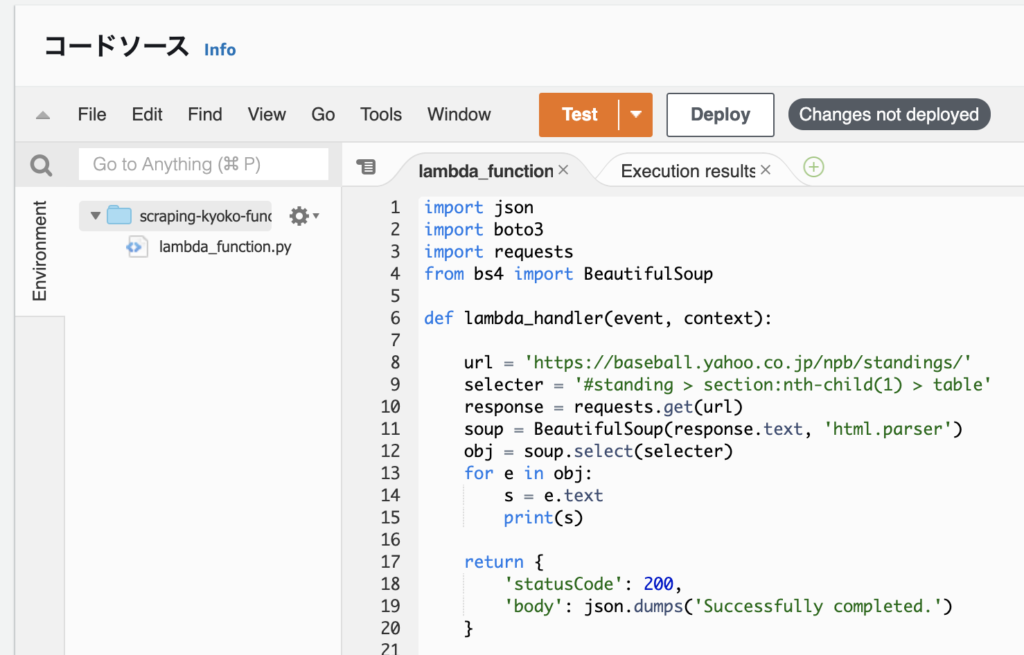
ソースコードは以下の通り。20行で動作するのが素晴らしい。
import json
import boto3
import requests
from bs4 import BeautifulSoup
def lambda_handler(event, context):
url = 'https://baseball.yahoo.co.jp/npb/standings/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.select("#standing > section:nth-child(1) > section > table")
for e in obj:
s = e.text
print(s)
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}
「Deploy」ボタンで保存後、「Test」ボタンをクリックすると、以下のように出力される。
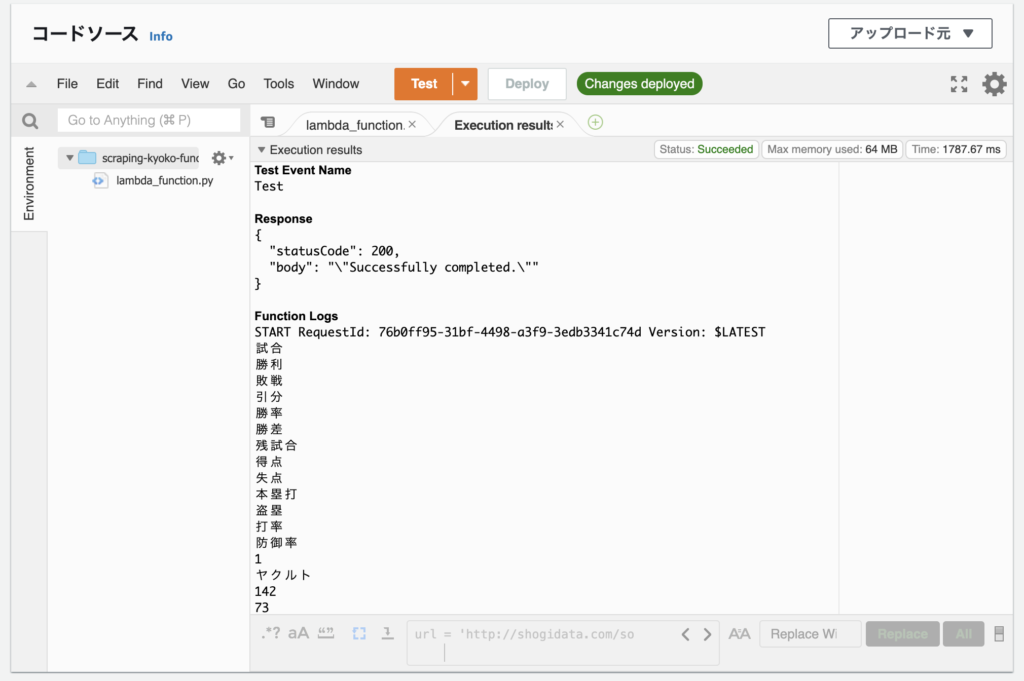
試合
勝利
敗戦
引分
勝率
勝差
残試合
得点
失点
本塁打
盗塁
打率
防御率
1
ヤクルト
142
73
51
18
.589
優勝
1
618
522
141
70
.254
3.44
2
阪神
143
77
56
10
.579
0.5
0
541
508
121
114
.247
3.30
(以下、略)
Lambda1:DynamoDBにスクレイピング結果を登録
スクレイピングした結果をDynamoDBに追加(存在すれば更新)する。NoSQLのため、InsertやUpdateを意識しないで済む。単純な構造のメリットである。
その前に、Lambda関数にDynamoDBの権限を付与する。「設定」タブ→左メニューの「アクセス権限」から、ロール名リンクをクリック。
「ポリシーをアタッチします」ボタンをクリック。
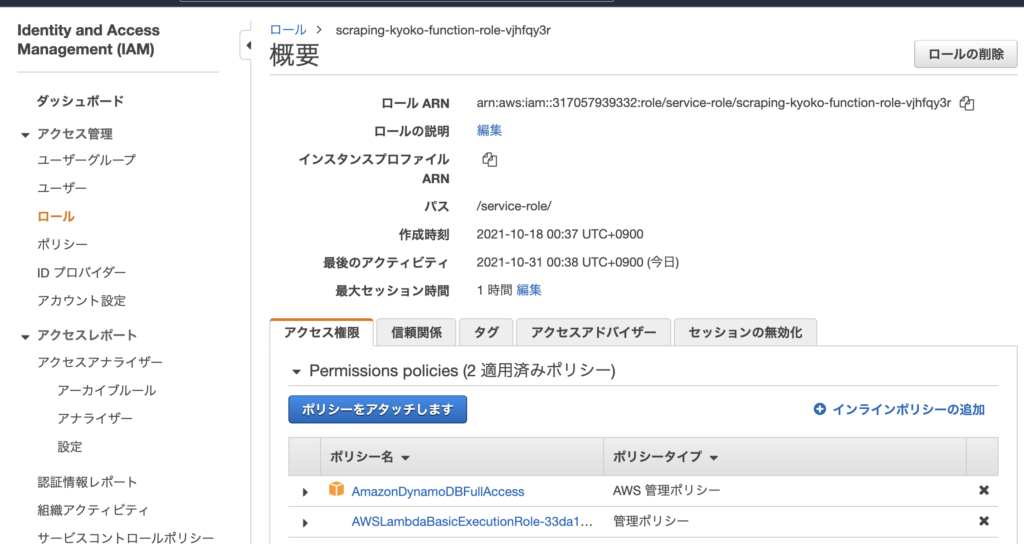
「DynamoDB」と入力し、「AmazonDynamoDBFullAccess」にチェックをつけ、「ポリシーのアタッチ」ボタンをクリック。これでLambda関数がDynamoDBにアクセスすることができるようになる。
そして、スクレイピングしたデータをDynamoDBに追加(存在すれば更新)する。
import json
import boto3
import requests
from bs4 import BeautifulSoup
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
def lambda_handler(event, context):
try:
mail = 'twinkangaroos@gmail.com'
contents_name = 'YahooTigers'
url = 'https://baseball.yahoo.co.jp/npb/standings/'
selecter = '#standing > section:nth-child(1) > table'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.select(selecter)
contents = ''
for e in obj:
contents += e.text
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'UpdateFlag': 1,
'Contents': contents,
'Sabun': '',
'URL': url,
'Selecter': selecter
}
)
except Exception as e:
print('Error!')
print(e)
raise e
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}DynamoDBの「項目」からテーブルの情報を確認すると、データが入っている。
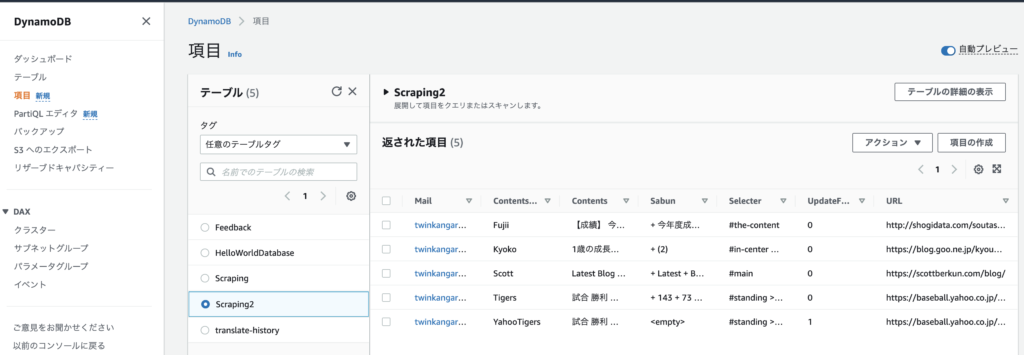
さらに以下の処理を追加する。
- URLとSelecterを複数処理できるようループ処理を追加する。
- Scraping2テーブルから過去にスクレイピングした本文を取得する。
- 最新データと2)のデータを比較して差分があった場合、DynamoDBに追加(更新)。
import json
import urllib.parse
import boto3
import datetime
from datetime import timedelta, timezone
import random
import os
import requests
from bs4 import BeautifulSoup
import difflib
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
def lambda_handler(event, context):
mail = 'twinkangaroos@gmail.com'
contents_name = ['YahooTigers']
url = [
'https://baseball.yahoo.co.jp/npb/standings/'
]
selecter = [
'#standing > section:nth-child(1) > table'
]
for i in range(len(url)):
state = main(mail, contents_name[i], url[i], selecter[i])
if state == False:
return {
'statusCode': 200,
'body': json.dumps('Process aborted becaouse an error occurred. ' + contents_name)
}
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}
def main(mail, contents_name, url, selecter):
file_contents = ''
state = ''
exist_contents = ''
try:
#Get existing data
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
exist_contents = exist_data['Item']['Contents']
except KeyError:
print('Not found data. OK. Insert new data.')
except Exception as e:
print('Select DB Error!!!')
print(e)
return False
file_contents = scraping_selecter(contents_name, url, selecter)
if file_contents == False:
return False
try:
if file_contents != exist_contents:
print('changed!')
state = 'changed!'
res = difflib.ndiff(exist_contents.split(), file_contents.split())
sabun = ''
for r in res:
if r[0:1] in ['+']:
sabun = sabun + r + '\n'
#if the data has been altered,
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'UpdateFlag': 1,
'Contents': file_contents,
'Sabun': sabun,
'URL': url,
'Selecter': selecter
}
)
else:
print('same...')
state = 'same...'
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
return False
return state
#Get data by scraping.
def scraping_selecter(contents_name, url, selecter):
file_contents = ''
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.select(selecter)
for e in obj:
file_contents = e.text
if file_contents == '':
return False
except Exception as e:
print('Scraping Error!!! ' + contents_name)
print(e)
return False
return file_contents
これで、差分があった場合にDynamoDBに「UpdateFlag」を1で更新することにより、更新があったことを示す。
次に、「UpdateFlag」を1の場合に、メールで通知するLambdaを作成する。
Lambda2:DynamoDBからデータを取得し、差分があったらメール送信
DynamoDBから「UpdateFlag」を取得し、1の場合に差分があったとみなし、メールで通知する。その後、「UpdateFlag」を0にリセットする。
import json
import boto3
sns_client = boto3.client('sns')
dynamodb = boto3.resource('dynamodb')
scraping_table2 = dynamodb.Table('Scraping2')
sns_client = boto3.client('sns')
def lambda_handler(event, context):
mail = 'twinkangaroos@gmail.com'
contents_name = ['YahooTigers']
contents_flag = [True]
sabun_flag = [False]
for i in range(len(contents_name)):
state = main(mail, contents_name[i], contents_flag[i], sabun_flag[i])
if state == False:
return {
'statusCode': 200,
'body': json.dumps('Process aborted becaouse an error occurred. ' + contents_name)
}
return {
'statusCode': 200,
'body': json.dumps('The Notify process is complete.')
}
def main(mail, contents_name, contents_flag, sabun_flag):
update_flag = 0
contents = ''
sabun = ''
url = ''
selecter = ''
# Check it has been updated.
try:
#Get existing data
exist_data = scraping_table2.get_item(
Key={
'Mail': mail,
'ContentsName': contents_name
}
)
update_flag = exist_data['Item']['UpdateFlag']
contents = exist_data['Item']['Contents']
sabun = exist_data['Item']['Sabun']
url = exist_data['Item']['URL']
selecter = exist_data['Item']['Selecter']
except KeyError:
print('Not found data. OK. Do nothing.')
except Exception as e:
print('Select Error!!!')
print(e)
return False
if update_flag != 1:
print('No change, so normal termination.')
return True
print('change!')
body = contents_name + '\n\n' + url + '\n\n'
if contents_flag == True:
body = body + contents + '\n\n'
if sabun_flag == True:
body = body + sabun + '\n\n'
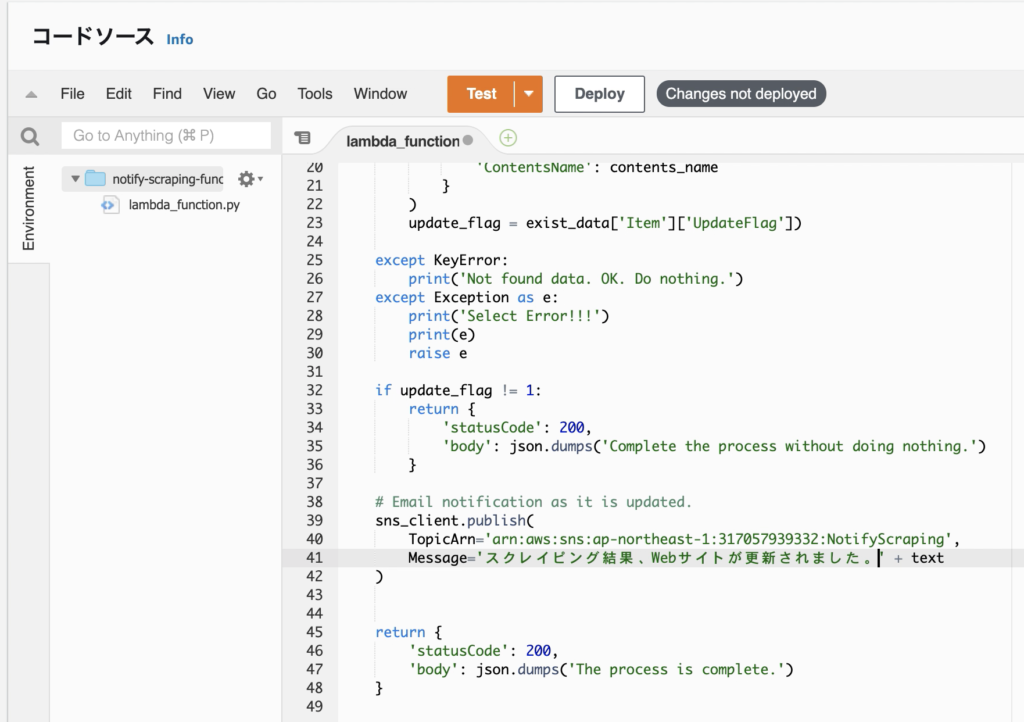
# Email notification as it is updated.
sns_client.publish(
TopicArn='arn:aws:sns:ap-northeast-1:317057939332:NotifyScraping',
Message='The website has been updated as a result of scraping. ' + '\n\n' + body
)
# Reset the UpdateFlag.
try:
response = scraping_table2.put_item(
Item={
'Mail': mail,
'ContentsName': contents_name,
'UpdateFlag': 0,
'Contents': contents,
'Sabun': sabun,
'URL': url,
'Selecter': selecter
}
)
except Exception as e:
print('Insert(Update) Error!!!')
print(e)
raise False
return True
前述したように、SNSの権限もLambdaに付与する。「設定」タブの「アクセス権限」から、ロール名のリンクをクリック後、「ポリシーをアタッチします」から「AmazonSNSFullAccess」の権限を付与する。付与後の画面は以下。
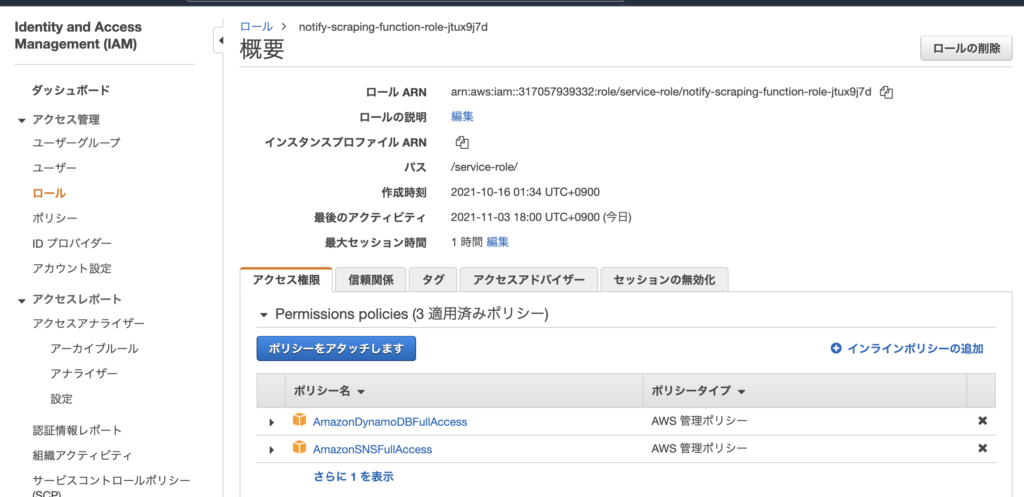
これにて実装完了。まとめると以下になる。
- 【Amazon EventBridge】crontabを設定する(例えば1時間毎にStep Functionsを実行するなど)。
- 【StepFunctions】Lambda関数(差分取得Lambdaとメール通知Lambda)を順番に呼び出す。
- 【Lambda関数1】差分取得Lambda
- 【Lambda関数2】メール通知Lambda
長くなったが、個人的には、Lambdaを利用することのメリットを非常に感じた。サーバーレス、マイクロサービスの技術により、アプリケーション開発者は機能の実装に集中することができる。これらの技術に触れて感じたのは、Amazonがいかに開発者に対して簡単に開発できるかを気にかけており、極力余分な設定は暗黙的に吸収し、必要最低限の設定でプログラム開発ができるようになっている。
一昔前の開発においては、まず開発環境を作ることに時間がかかった。そしてOSの設定やミドルウェアの設定を気にしながらの開発であったため、Apacheのhttpd.confの設定を気にしたり、php.iniの文字コードの設定を気にしたり、様々な些末な要素をクリアした上でないと開発ができなかった。
それらの開発者が感じるストレスを感じさせない仕組みづくりに力を入れているAmazonの姿勢は素晴らしく、GoogleCloudに比べると1歩も2歩も先を行っているように感じる。
残念なのがこれらの技術を触れることなく、既存のモノリシック(一枚岩)のWebアプリを作りがちであり、それらの技術を最大限生かせるような人材がどれくらいいるのだろうか。かくいう私もこれらの技術を業務時間内に取得する時間はなく、プライベートの時間に半分遊びながら学んでいるという感じであり、なかなか業務で本格的に活かそうと思うとそれなりの時間を確保する必要があるが、日々の業務で多忙なエンジニアにそれを会社として求めるのは難しい場合が多い。そのためこれらの情報が役に立つ、もしくは何らかのショートカットができたということであれば、それは望外の喜びである。
次回は、スクレイピングである収穫を得られたのでそれを紹介しようと思う。
SNS(Simple Notification Service)の設定(※2022/2/15追記)
SNS(Simple Notification Service)の設定を記述し忘れていたので追記する。
トピックの作成
Amazon SNS(Simple Notification Service)から「トピックの作成」ボタンをクリック。
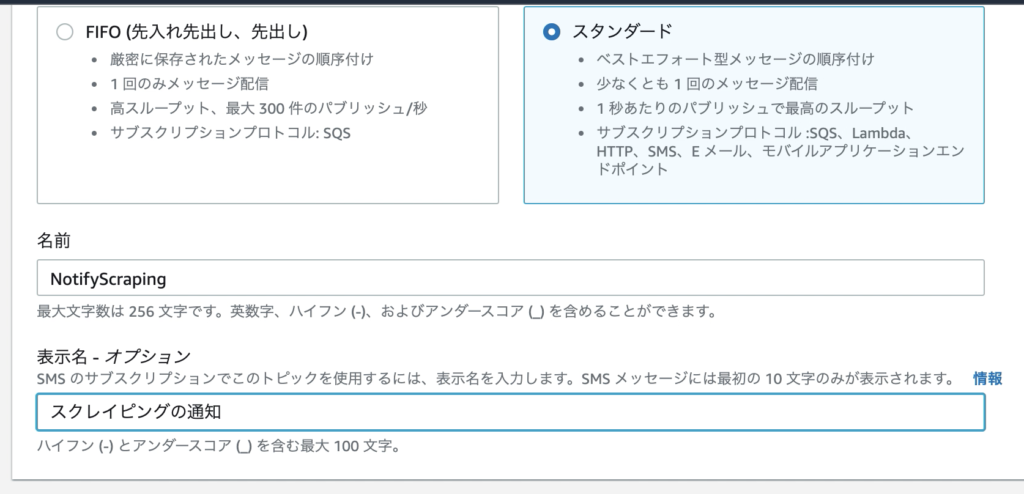
「スタンダード」を選択し、名前と表示名を入力する。
他は特に変更せず、「トピックの作成」ボタンクリック。
サブスクリプションの作成
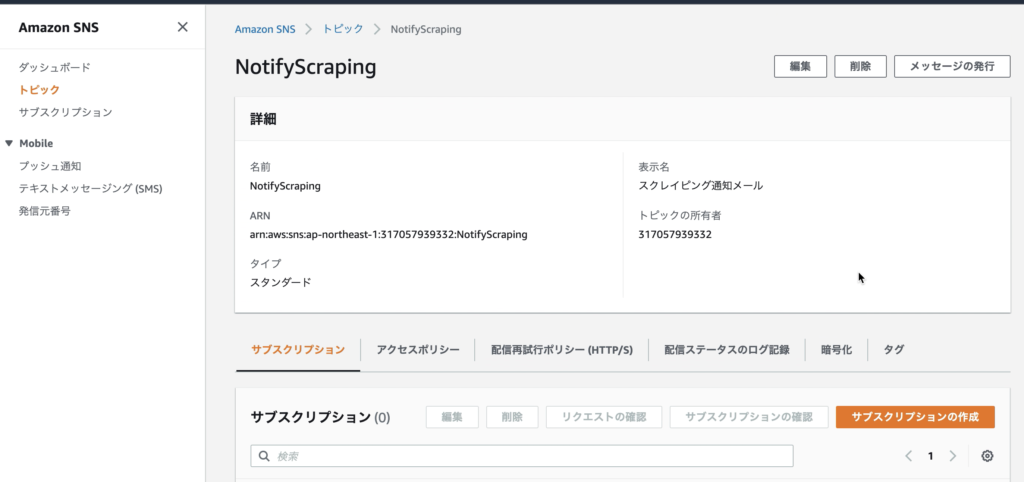
トピックの作成は完了。続いて「サブスクリプションの作成」ボタンをクリック。
「プロトコル」の中から「Eメール」を選択し、「エンドポイント」に自分のメールアドレスを入力。その後、「サブスクリプションの作成」ボタンをクリック。
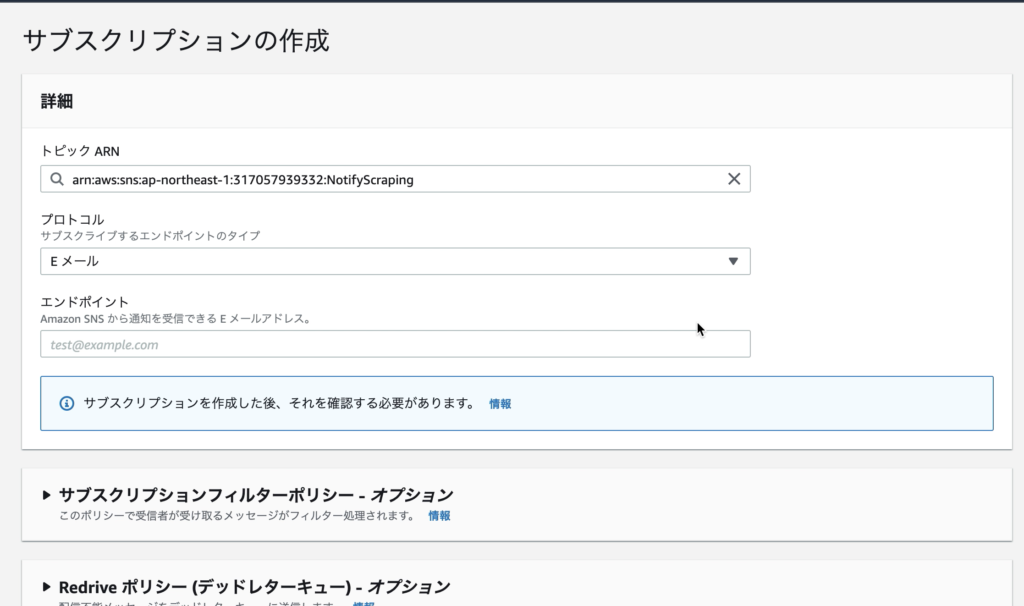
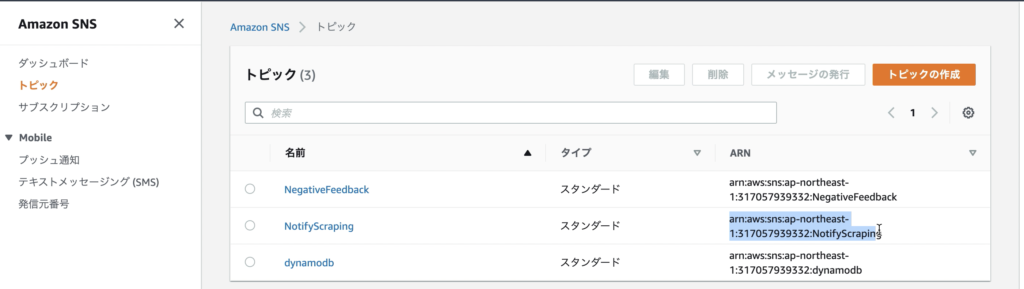
そして、作成したトピックの「ARN」をコピーしておく(Lambdaで利用するため)。
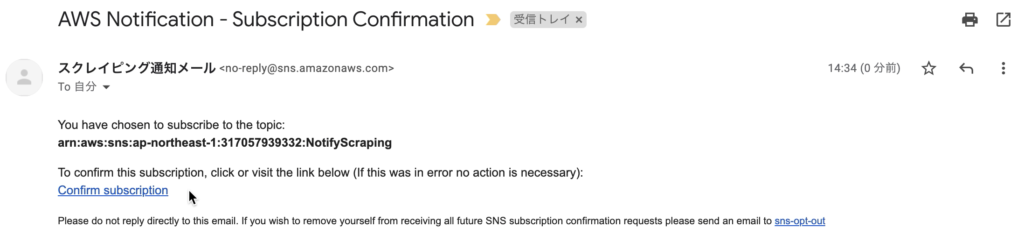
先ほどのメールアドレスにメールが届いているので、「Confirm subscrition」をクリックする。
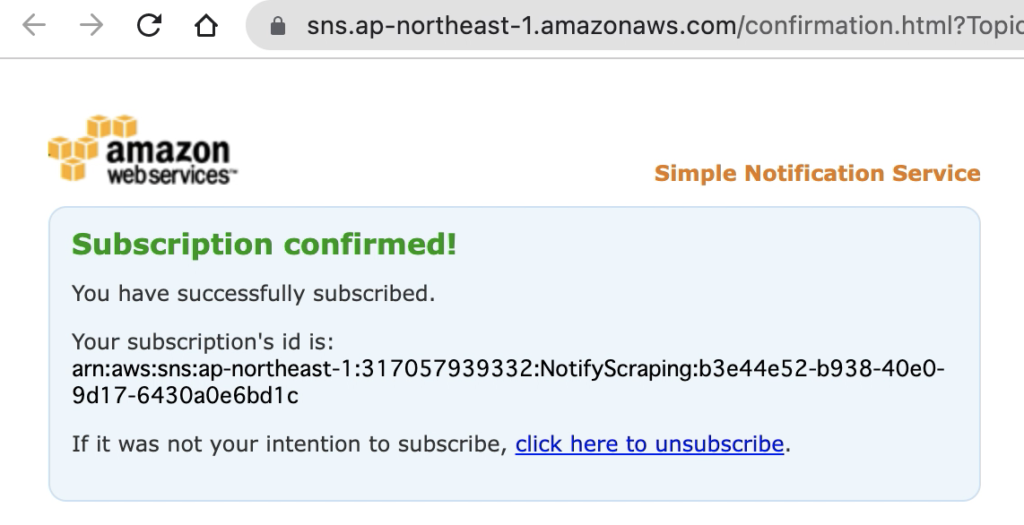
クリックすると成功。
トピックの呼び出し(publish)
前述の通り、sns_client.publish() のパラメータに先ほどのARNをセットすることで、メール通知するできる。
トピックとサブスクリプションの関係は以下の通り。
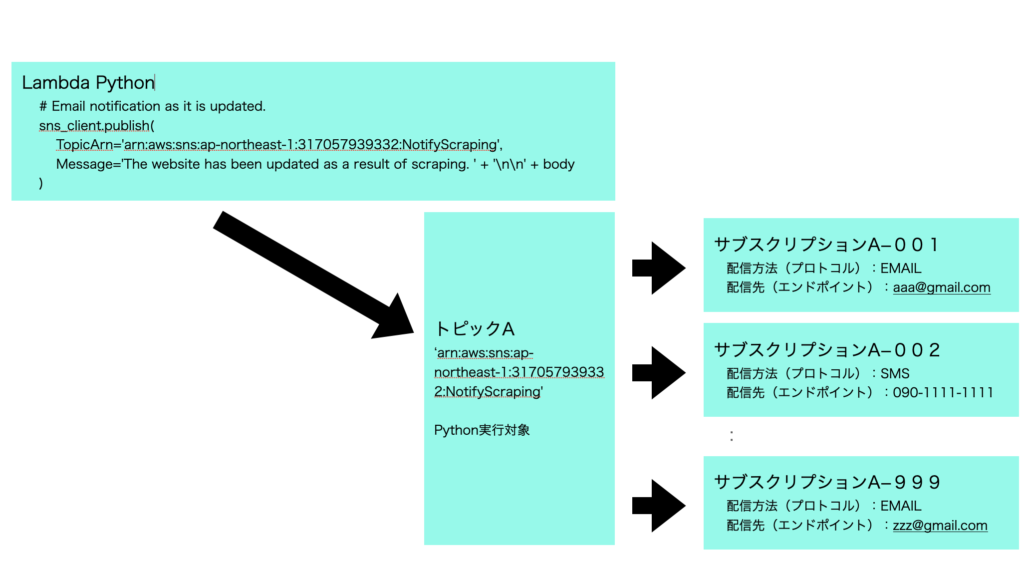
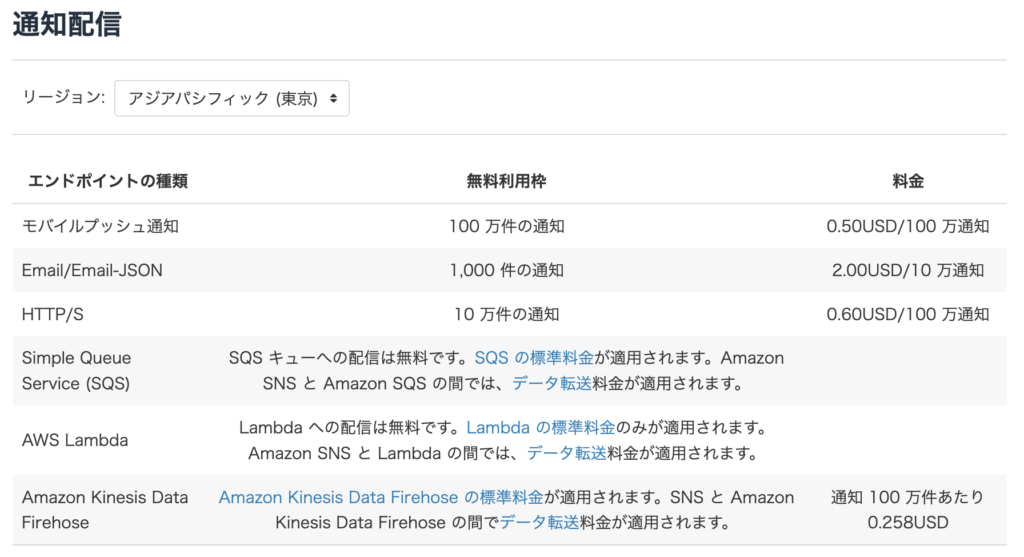
従来、メルマガ配信など複数ユーザーにメール配信するためには別途ASPの契約を行うことが一般的だが、AmazonSNSを利用すれば、低価格で実施できる。
■料金 – Amazon SNS | AWS
https://aws.amazon.com/jp/sns/pricing/