Yahooニュースのコメントって酷いって思いませんか?例えば、Yahooニュース『眞子さんの心労ピークか 夫の不合格、祖父の死去…”お使え”できない宮内庁は後悔』の 12,593件(2021/11/12時点)のコメントは多すぎて読む気になれないし、『お爺様のことは仕方ないけど、そういう旦那を選んだのは自分自身だからね。そういうことを含めて「自己責任」って言うんですよ、一般の社会では。』という上から目線のコメントに対して 172,705件の「そう思う」の世界観も理解できない。このようにネガティブな印象を持っている中、興味深いニュースのコメントからはユーザーの本音を知ることができるメリットを発見した。仕事柄、貴重なユーザーインサイトを得ることができるのではないかと。そのコメントを効率的に得る方法を残す。

目次
『”絵本の読み聞かせ”9割がツラいと回答』
注目した記事は、「“絵本の読み聞かせ”9割がツラいと回答… 親の理想と現実に臨床心理士「無理なく工夫することも大事」(ABEMA TIMES) – Yahoo!ニュース」。あるプロジェクトで、「絵本の読み聞かせをする保護者は、読み聞かせに対してどう考えているのだろう?ポジティブ?ネガティブ?どんな気持なのだろう?」と、カスタマージャーニーを描く上で、彼女ら(今回ターゲットとなる顧客はほとんどが女性である)のインサイトに興味があった。そしてこの記事を読んで絵本を読み聞かせることに対して「辛い」と感じる人が多いことに驚いた(多少脚色してあるものの)。私は読み聞かせの経験がないので彼女らの気持ちを知りたくて、Yahooコメント194件を抽出し、熱意があるであろう文字数の多い順に読むことにした。
対象URLを取得
前回の記事「AWS Lambdaで定期的にスクレイピングする方法(その3:Lambda・DynamoDB・Simple Notification Service編)」でLambdaでスクレイピングを行ったが、方法はほぼ同じである。
対象URLを取得する際、Yahooニュースのコメントの「もっと見る」をクリック後・・・

以下のURLに遷移するが、このままでは記事の取得はできない。
https://news.yahoo.co.jp/articles/d5c8bcaaea5516d335a06bcf9e61ee387b64d31d/comments
理由は、iframeで表示されているためである。そのため、ifame内のURLを取得する必要がある。

iframeのsrc=”” をコピーし、テキストエディタで、「&」を「&」に置換する(ua=はカットしているがあっても問題なし)。
https://news.yahoo.co.jp/comment/plugin/v1/full/?origin=https%3A%2F%2Fnews.yahoo.co.jp&sort=lost_points&order=desc&page=1&type=t&topic_id=20210911-00010001-abema&space_id=2079510507&content_id=&full_page_url=https%3A%2F%2Fheadlines.yahoo.co.jp%2Fcm%2Fmain%3Fd%3D20210911-00010001-abema-soci&comment_num=10&ref=&bkt=&flt=2&grp=&opttype=&disable_total_count=&compact=&compact_initial_view=&display_author_banner=off&mtestid=&display_blurred_comment=off
そうすると以下のように直接ページを参照することができる。
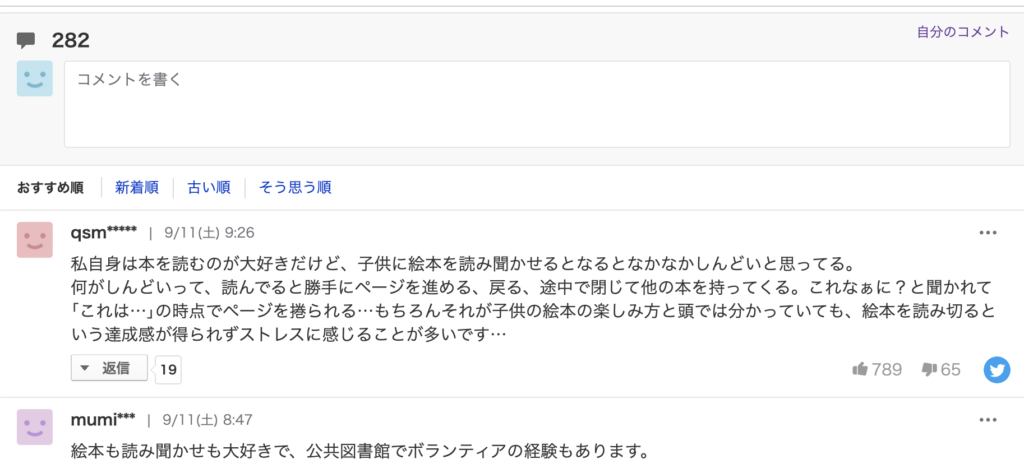
対象タグの取得
前回は、セレクターで1箇所のみ取得したが、今回は1ページに複数あるため、class名とタグ名を指定して取得するBeautifulSoupのfind_all()メソッドを使うことにした。対象箇所は以下の通り、<span>タグの”cmtBody”というクラス名を指定する。
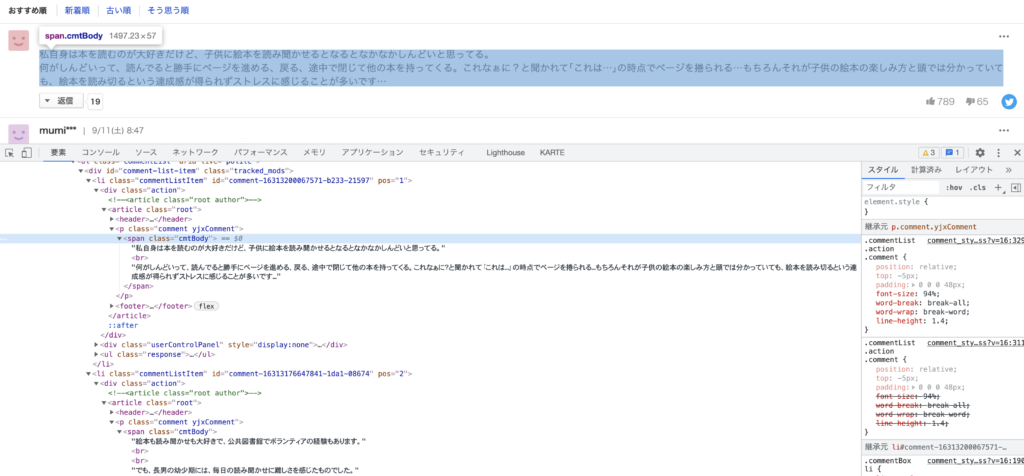
DynamoDBの設定
詳細は前回の記事に記載があるので割愛するが、テーブル名「ScrapingYahooComment」を作っておく。パーティションキーは、「ContentsName (String)」、ソートキーは、「No (Number)」とする。
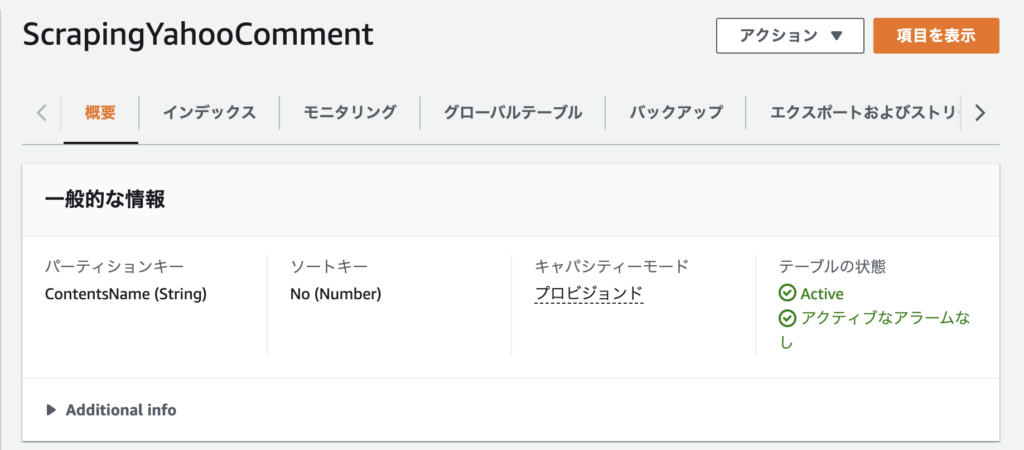
ポリシーをアタッチ
こちらも前回の記事と同様、DynamoDBと、感情分析用のComprehendの権限を付与しておく。
Lambdaでスクレイピング
以下のソースコードでスクレイピングする。ついでに各コメントに対して感情分析を行う。Amazon Comprehendのdetect_sentiment()メソッドを使い、ポジティブなのかネガティブなのかを取得し、DynamoDBに保存する。APIはこちらを参考に。
import json
import boto3
import requests
from bs4 import BeautifulSoup
dynamodb = boto3.resource('dynamodb')
scraping_table = dynamodb.Table('ScrapingYahooComment')
comprehend_client = boto3.client('comprehend')
def lambda_handler(event, context):
try:
contents_name = 'YahooEhon'
j = 1
tag = 'span'
p_class = 'cmtBody'
for i in range(20):
url = 'https://news.yahoo.co.jp/comment/plugin/v1/full/?origin=https%3A%2F%2Fnews.yahoo.co.jp&page=' + str(i+1) + '&sort=lost_points&order=desc&type=t&topic_id=20210911-00010001-abema&space_id=2079842622&content_id=&full_page_url=https%3A%2F%2Fheadlines.yahoo.co.jp%2Fcm%2Fmain%3Fd%3D20210911-00010001-abema-soci&comment_num=10&ref=&bkt=&flt=2&grp=&opttype=&disable_total_count=&compact=&compact_initial_view=&display_author_banner=off&mtestid=&display_blurred_comment=off'
file_contents = scraping_tag_class(contents_name, url, tag, p_class)
if file_contents == False:
return {
'statusCode': 500,
'body': json.dumps('Error occured. ' + contents_name)
}
for contents in file_contents:
response = comprehend_client.detect_sentiment(
Text=contents,
LanguageCode='ja'
)
sentiment = response['Sentiment']
positive = response['SentimentScore']['Positive']
negative = response['SentimentScore']['Negative']
response = scraping_table.put_item(
Item={
'ContentsName': contents_name,
'No': j,
'Contents': contents,
'Sentiment': sentiment,
'Positive': int(positive*100),
'Negative': int(negative*100),
'Length': len(contents)
}
)
j += 1
except Exception as e:
print('Error!')
print(e)
raise e
return {
'statusCode': 200,
'body': json.dumps('Successfully completed.')
}
def scraping_tag_class(contents_name, url, tag, p_class):
file_contents = []
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
obj = soup.find_all(tag, class_=p_class)
for e in obj:
file_contents.append(e.text)
if len(file_contents) == 0:
print('not found..')
return False
except Exception as e:
print('Scraping Error!!! ' + contents_name)
print(e)
return False
return file_contents
実行後、DynamoDBを確認すると以下のようにデータが格納されている。
「アクション」ボタンから、「結果をCSVにダウンロードする」ボタンをクリックすると、CSVダウンロードできる。
CSVダウンロード結果
CSVはUTF-8のため、Shift-JISに変換し、Excelで確認すると以下のようになる。

感情分析はまだ発展途上のためか、人間の目から見て「?」となることも多いため、参考程度になる。
今回のような記事であればコメントも他人に対する攻撃ではなく「自分」の体験を述べるためそれほど心理的なダメージはなかった。多くの人が読み聞かせに対して無理をしなくてもいい、というアドバイスをしており、例えば以下のように相談される立場の人のコメントなどは参考になると思う。
https://news.yahoo.co.jp/articles/d5c8bcaaea5516d335a06bcf9e61ee387b64d31d
お母さんたちに本の選び方などを相談されることが多い立場なのですが、それで常々感じているのは、皆さん難しく考えすぎなのではないかということ。読み聞かせを通じて何かを教えなくては!という意識の強い方が多いので、子どもにとって難しい本を選んでしまい、喜ばれない→読む方も楽しくないという悪循環に陥っている気がします。大人が子どもに読ませたいと思う本は、たいていその子の発達段階にはちょっと早くて難しい傾向があるようで…。親子で楽しめるのが一番なので、難しく考えないで、ご自分が読みたい本、お子さんが好きな本を読んであげてくださいと言っています。
このようにブラウザやスマートフォンから各コメントを見ていくのは面倒だが、この方法を使えば一気に情報を取得し、効率よく内容を確認できるので、一般ユーザーのインサイトを知りたい場合におすすめである。